Interactive SkLearn Series - Anomaly Detection
Identify the rare and the strange. We’ll apply Isolation Forests and One-Class SVMs to detect outliers, useful for fraud detection, network security, and cleaning training data.
Interactive SkLearn Series - Manifold Learning
Visualize the impossible. We’ll use t-SNE and UMAP to map high-dimensional datasets into 2D or 3D space, revealing local structures and clusters that linear methods like PCA miss.
Interactive SkLearn Series - Dimensionality Reduction
Simplify complex data. We’ll use PCA to project high-dimensional data into fewer components, reducing noise and speeding up training while preserving variance.
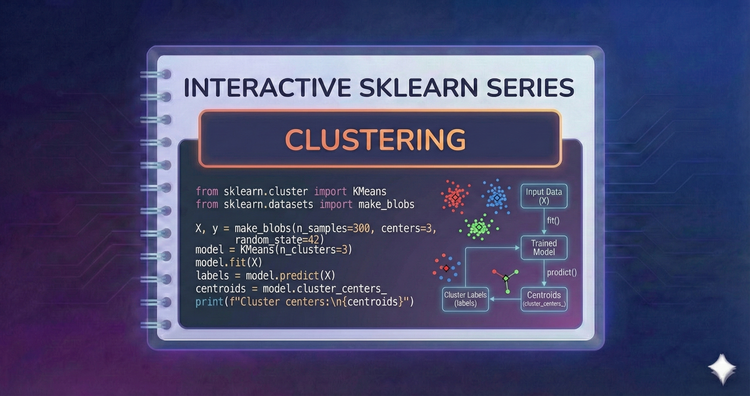
Interactive SkLearn Series - Clustering
Discover hidden groups. We’ll use K-Means for centroid-based grouping, DBSCAN to find arbitrary shapes and outliers, and Hierarchical Clustering to build taxonomies.
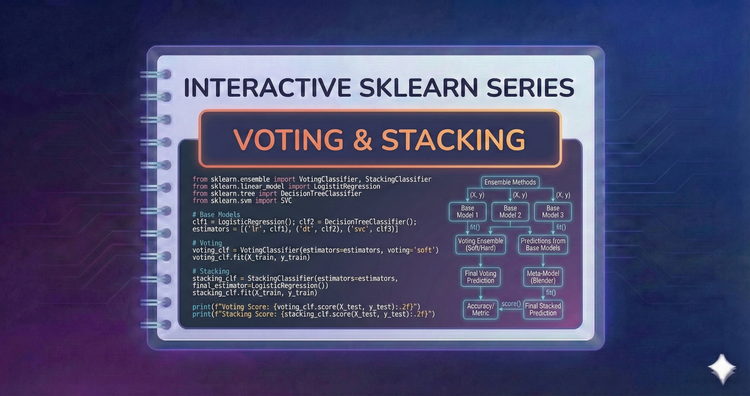
Interactive SkLearn Series - Voting and Stacking
Two heads are better than one. We’ll use Voting Classifiers to average predictions and Stacking to train a meta-model that learns how to best combine the outputs of diverse base models.
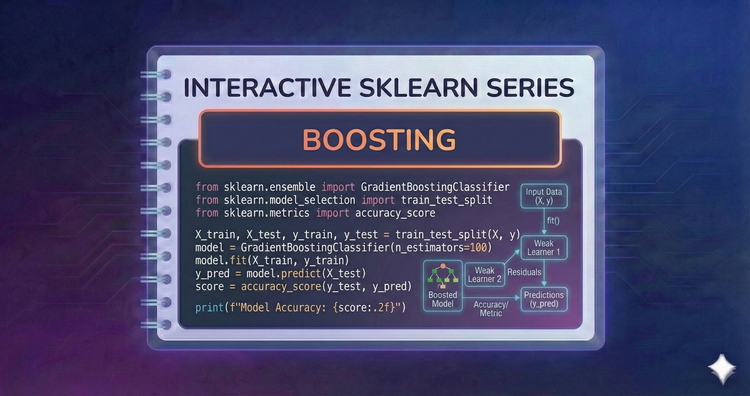
Interactive SkLearn Series - Boosting
Reduce bias by learning from mistakes. We’ll implement AdaBoost and Gradient Boosting, and specifically look at Histogram-based Gradient Boosting for state-of-the-art speed on large data.
Interactive SkLearn Series - Bagging
Reduce variance by combining models. We’ll explore Random Forests and ExtraTrees, learning how they aggregate predictions from many decision trees to create a robust, stable estimator.
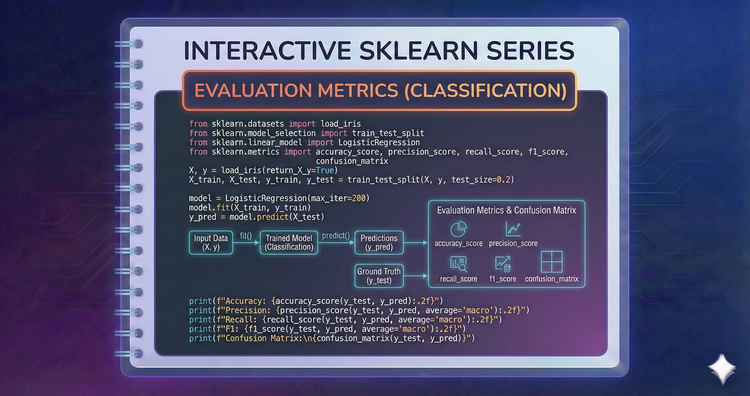
Interactive SkLearn Series - Evaluation Metrics (Classification)
Accuracy isn't everything. We’ll dive into Precision, Recall, and F1-Score for imbalanced datasets, and use ROC-AUC and Confusion Matrices to fully diagnose classifier performance.
Interactive SkLearn Series - Nearest Neighbors
Predict based on proximity. We’ll use K-Nearest Neighbors (KNN) for classification, understanding how distance metrics work and why the "curse of dimensionality" affects performance.
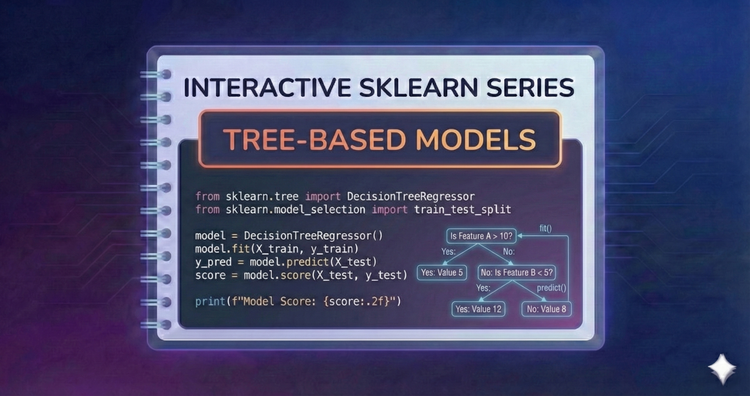
Interactive SkLearn Series - Tree-Based Models
Mimic human decision-making. We’ll visualize tree structures, understand splitting criteria like Gini impurity, and learn how to prune trees to prevent overfitting.