Object-Oriented Design Patterns in Python - Advanced Python OOP Review
Master Python’s object mechanics beyond standard classes. We’ll explore magic methods, the precise control of __slots__, and properties to write cleaner, more efficient Pythonic code.
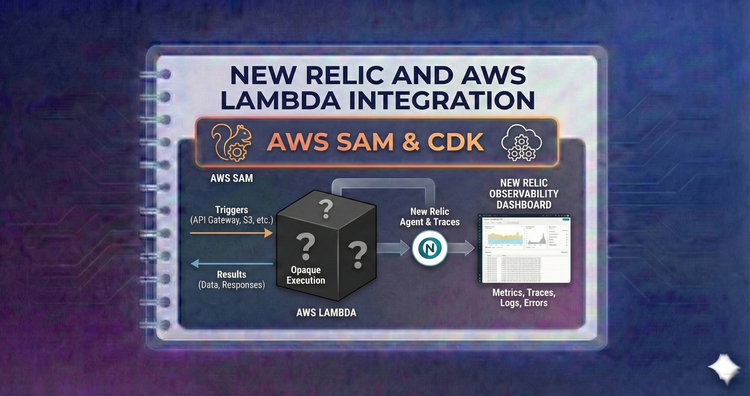
New Relic and AWS Lambda Integration - AWS SAM & CDK
Native AWS tooling support. Discover patterns for injecting the New Relic agent and extension into your CloudFormation templates and CDK constructs ensuring observability is baked in at the build phase.
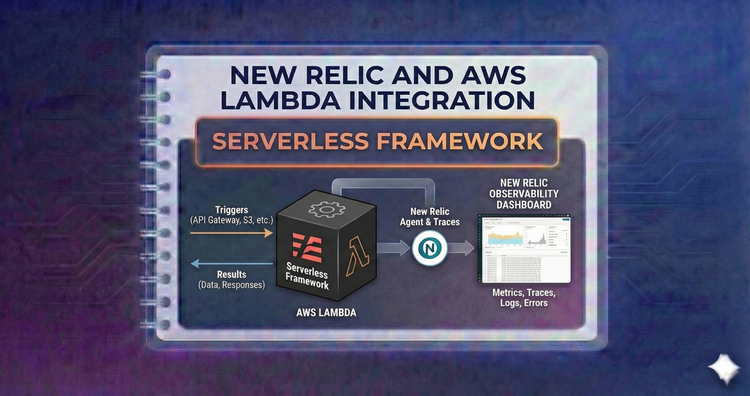
New Relic and AWS Lambda Integration - Serverless Framework
Streamline deployment. Utilize the serverless-newrelic-lambda-layers plugin to automatically inject instrumentation during your sls deploy process, keeping your serverless.yml clean and efficient.
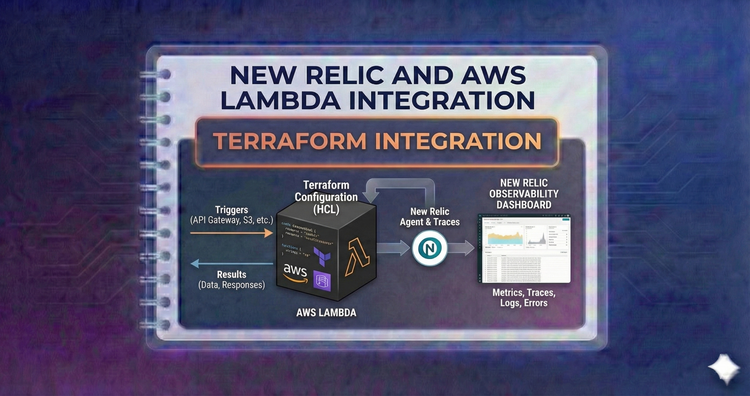
New Relic and AWS Lambda Integration - Terraform Integration
Automate observability. Use the newrelic Terraform provider to manage alert policies and entity tags, and learn to attach Lambda layers purely through Infrastructure as Code (IaC).
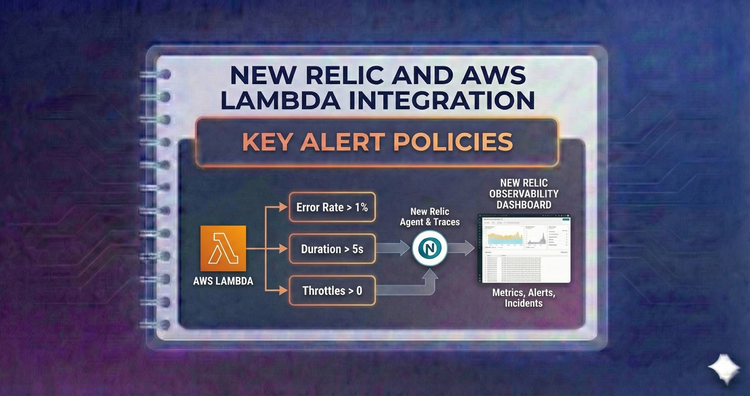
New Relic and AWS Lambda Integration - Key Alert Policies
Sleep soundly. We define the essential alerts every serverless team needs, including error rate spikes, throttling events, dead letter queue depth, and excessive duration warnings.
New Relic and AWS Lambda Integration - Dynamic Baseline Alerts
Static thresholds fail in dynamic environments. Configure alerts that learn your traffic patterns and only notify you when behavior deviates significantly from the norm, reducing alert fatigue.
New Relic and AWS Lambda Integration - NRQL for Serverless
Master the query language. Learn specific NRQL commands to query ServerlessSample data, calculating average duration, error rates, and throughput for specific functions or regions.
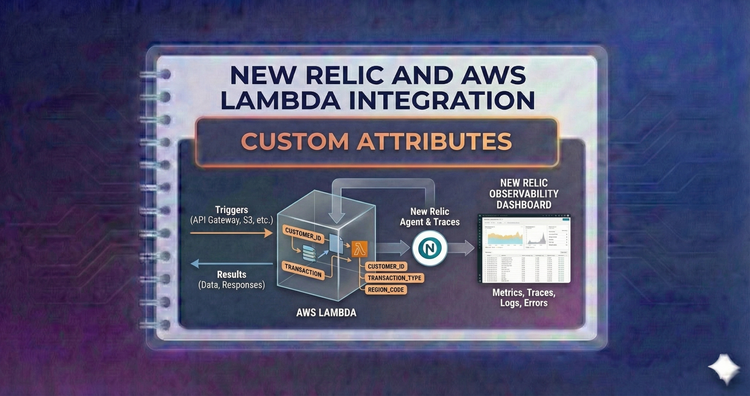
New Relic and AWS Lambda Integration - Custom Attributes
Add business context to code. Learn to tag invocations with data like userID or cartValue using recordCustomEvent, allowing you to connect technical performance directly to business outcomes.
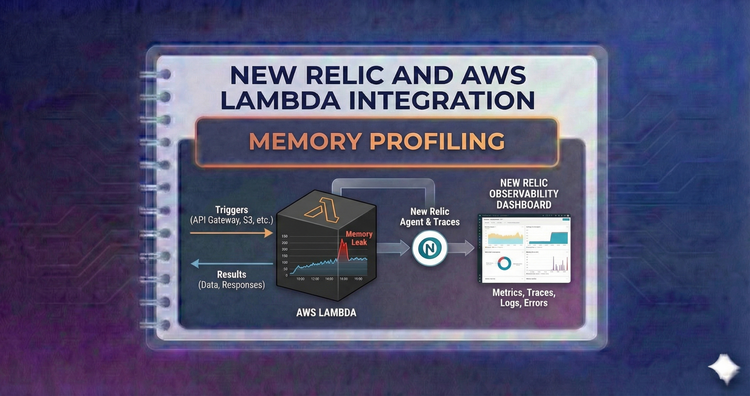
New Relic and AWS Lambda Integration - Memory Profiling
Stop guessing memory settings. Use the "Power Tuning" approach to visualize the relationship between allocated memory and duration, finding the sweet spot where performance meets cost efficiency.
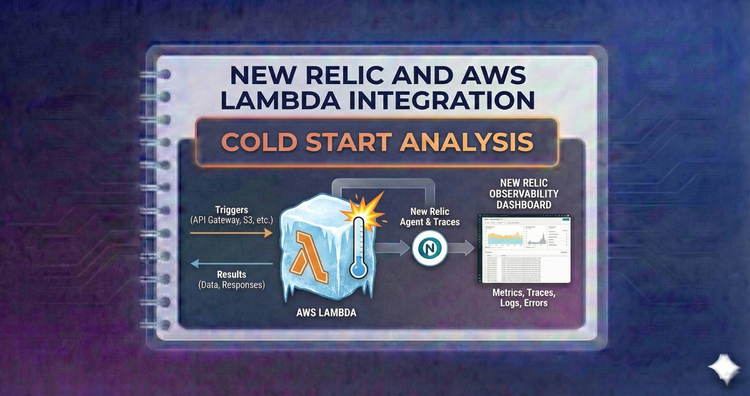
New Relic and AWS Lambda Integration - Cold Start Analysis
The serverless nemesis. Differentiate between initialization overhead and execution time. We analyze how bundle size and layers impact cold starts and when it is worth paying for Provisioned Concurrency.