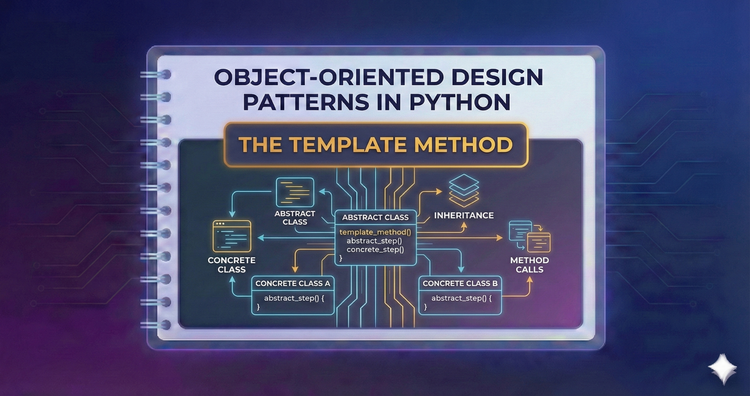
Object-Oriented Design Patterns in Python - The Template Method
Define the skeleton of an algorithm while letting subclasses fill in the details. A perfect pattern for enforcing structure while maximizing code reuse.
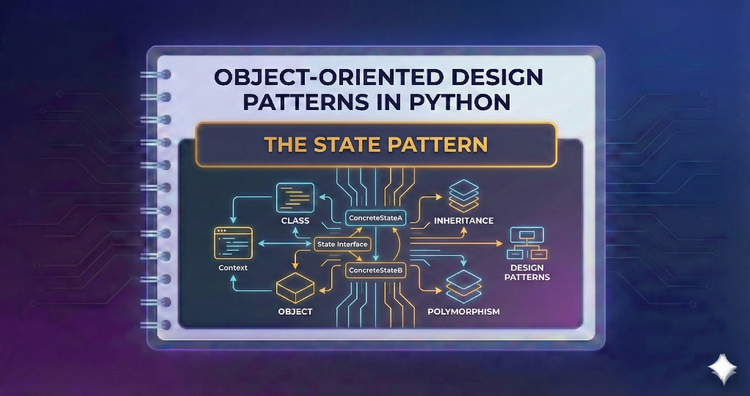
Object-Oriented Design Patterns in Python - The State Pattern
Allow objects to change their behavior when their internal state shifts. Learn to replace messy if-elif chains with clean, maintainable state-transition logic.
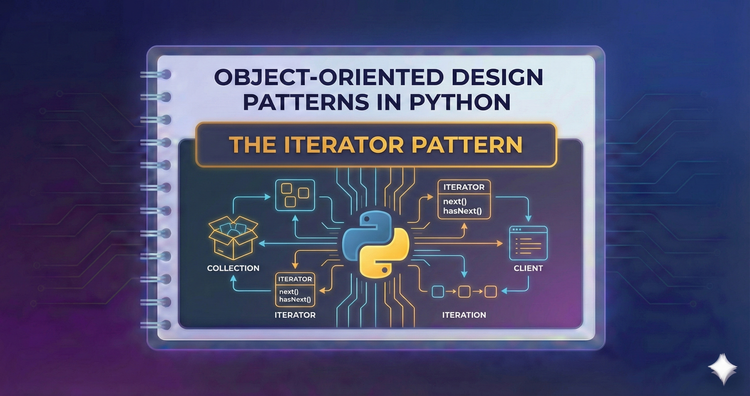
Object-Oriented Design Patterns in Python - The Iterator Pattern
Navigate collections without exposing internal structure. We will deep-dive into Python’s __iter__ and __next__, comparing traditional iterators with powerful Python Generators.
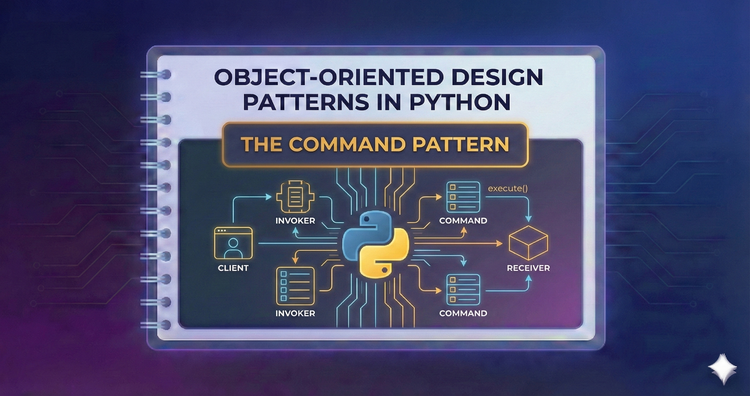
Object-Oriented Design Patterns in Python - The Command Pattern
Turn requests into stand-alone objects. We’ll explore how to encapsulate actions, enabling powerful features like job queues, transactional systems, and Undo/Redo mechanisms.
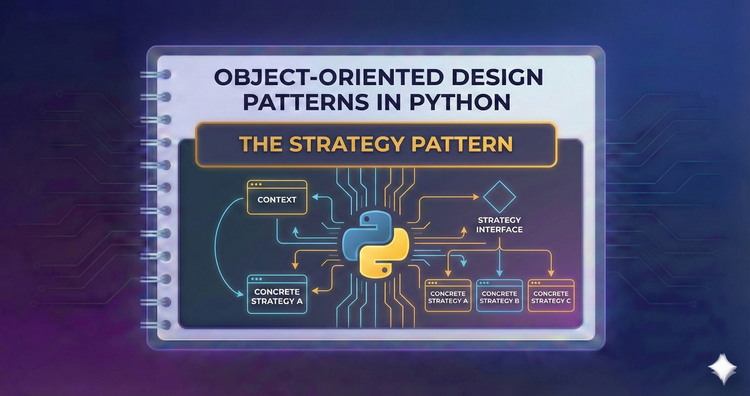
Object-Oriented Design Patterns in Python - The Strategy Pattern
Swap algorithms on the fly! Learn to encapsulate behaviors into interchangeable objects, and see how Python’s first-class functions can simplify this pattern to a single line.
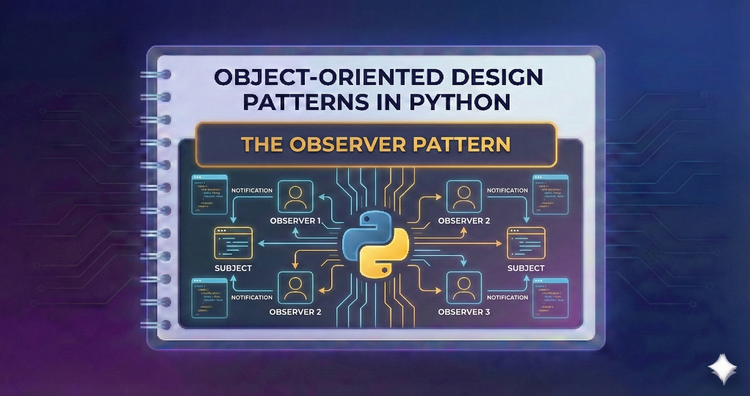
Object-Oriented Design Patterns in Python - The Observer Pattern
Stay in the loop with event-driven architecture. Master the publisher-subscriber model to notify multiple dependent objects automatically whenever a state change occurs.
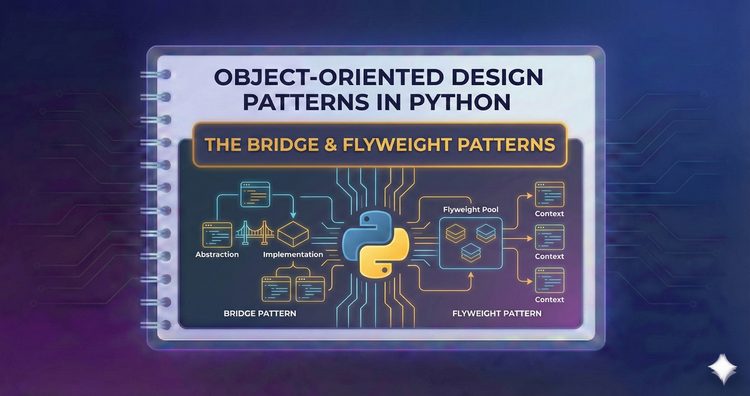
Object-Oriented Design Patterns in Python - The Bridge & Flyweight Patterns
Separate abstractions from implementations, and optimize RAM. Learn techniques to prevent class explosion and efficiently share data across thousands of objects.
Object-Oriented Design Patterns in Python - The Composite Pattern
Reader Mode
Reset
Prev
-- / --
Next
Introduction
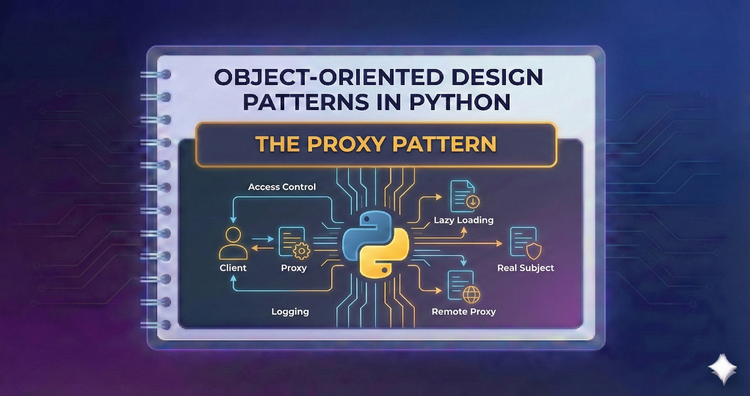
Object-Oriented Design Patterns in Python - The Proxy Pattern
Control access to an object with a surrogate. Explore how to use proxies for lazy initialization, security checks, and network requests, saving resources until they are truly needed.
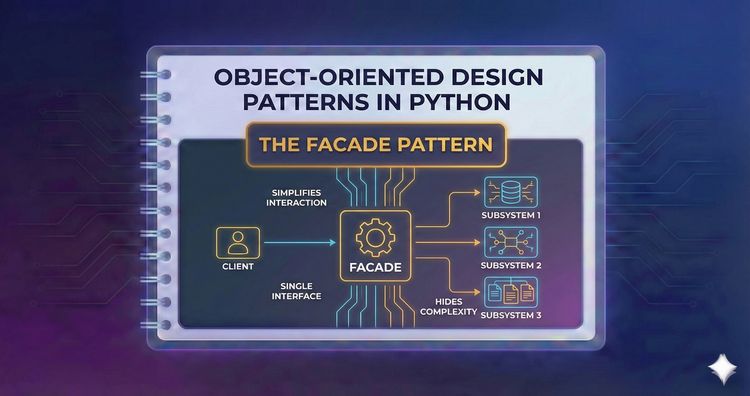
Object-Oriented Design Patterns in Python - The Facade Pattern
Hide complex subsystem logic behind a clean, simple interface. Learn how to design a "front door" for your heavy libraries, making them easier and safer for clients to use.