Interactive SkLearn Series - Permutation Importance
Meaningful interpretation. We’ll inspect model internals by shuffling feature values and measuring the drop in performance, determining which features truly drive predictions.
Interactive SkLearn Series - Text Feature Extraction
Turn text into math. We’ll use CountVectorizer for bag-of-words and TfidfVectorizer to weigh word importance, preparing raw text documents for machine learning algorithms.
Interactive SkLearn Series - Feature Selection
Less is often more. We’ll use Recursive Feature Elimination (RFE) and SelectFromModel to automatically identify and keep only the most predictive features, improving model speed.
Interactive SkLearn Series - Nested Cross-Validation
The gold standard for evaluation. We’ll implement Nested CV to separate hyperparameter tuning from model evaluation, providing an unbiased estimate of generalization error.
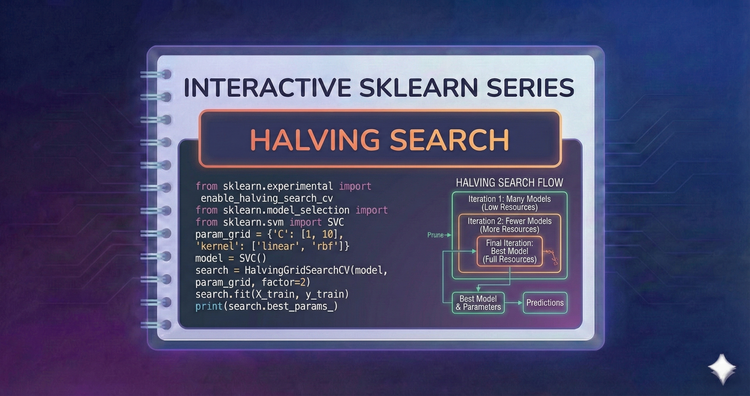
Interactive SkLearn Series - Halving Search
Speed up tuning with "successive halving." We’ll use HalvingGridSearchCV to quickly discard poor parameter combinations on small data subsets, focusing resources on promising candidates.
Interactive SkLearn Series - Randomized Search
Tune efficiently. When the search space is huge, RandomizedSearchCV samples a fixed number of configurations, often finding equal or better models than grid search in a fraction of the time.
Interactive SkLearn Series - Grid Search
Stop guessing parameters. We’ll use GridSearchCV to exhaustively test every combination of hyperparameters, finding the optimal configuration for your model automatically.
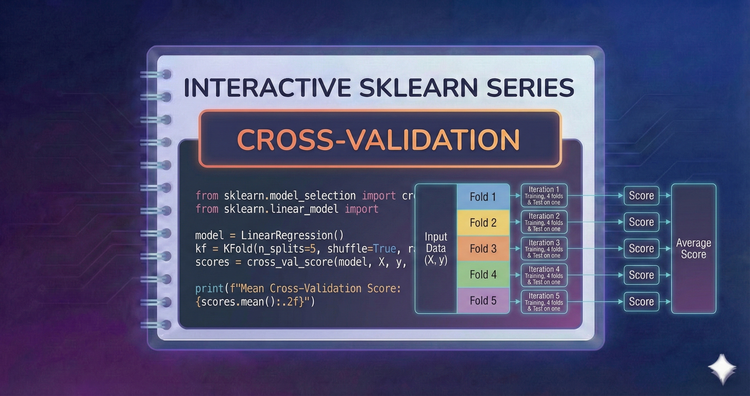
Interactive SkLearn Series - Cross-Validation
Validate with confidence. We’ll move beyond simple splits to K-Fold and Stratified K-Fold cross-validation, ensuring your model's performance metric is statistically robust and reliable.
Interactive SkLearn Series - Anomaly Detection
Identify the rare and the strange. We’ll apply Isolation Forests and One-Class SVMs to detect outliers, useful for fraud detection, network security, and cleaning training data.
Interactive SkLearn Series - Manifold Learning
Visualize the impossible. We’ll use t-SNE and UMAP to map high-dimensional datasets into 2D or 3D space, revealing local structures and clusters that linear methods like PCA miss.